Livelap Crawler: LivelapBot
Livelap is a content discovery app that indexes web content. Probably you have seen the Livelapbot/0.1 or LivelapBot/0.2 crawler in your server logs. LivelapBot can visit a page if it is shared on social media, and as part of its RSS/page crawling schedule.
What does LivelapBot collect
Livelap indexes web content and makes meta data and a link to your content available in livelap.com and in the Livelap app. For indexing we only use official HTML and media meta tags in your page. We don't scrape the contents of your articles. The following fields are used for indexing:
- Title
- Description
- Author
- Publication date
- Type of content (article, photo, video, etc)
- Images (og, twitter and other standard tags)
- Videos (og, twitter and other standard tags)
- RSS links
- Detect whether showing page in iframe is allowed
How does my content look in Livelap
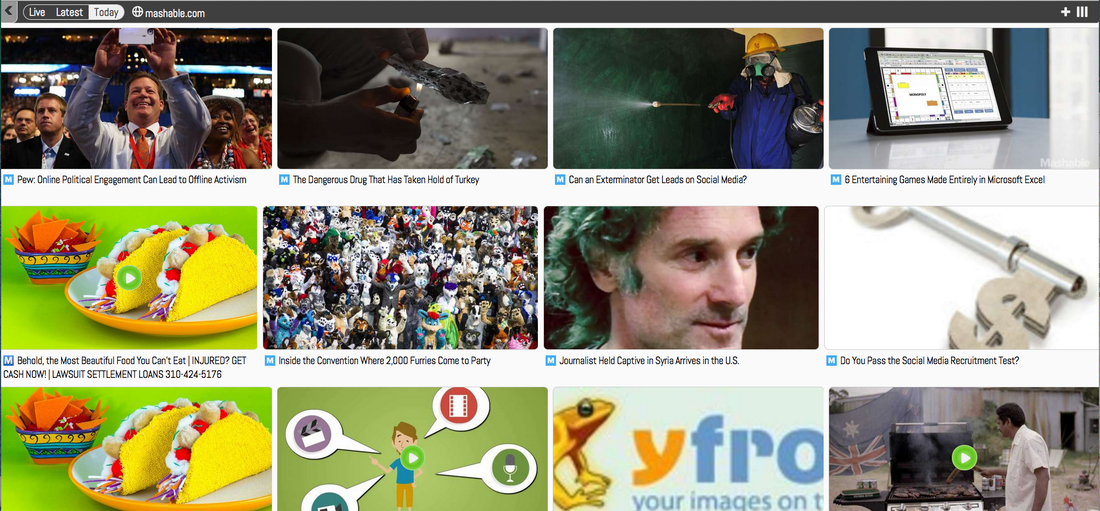
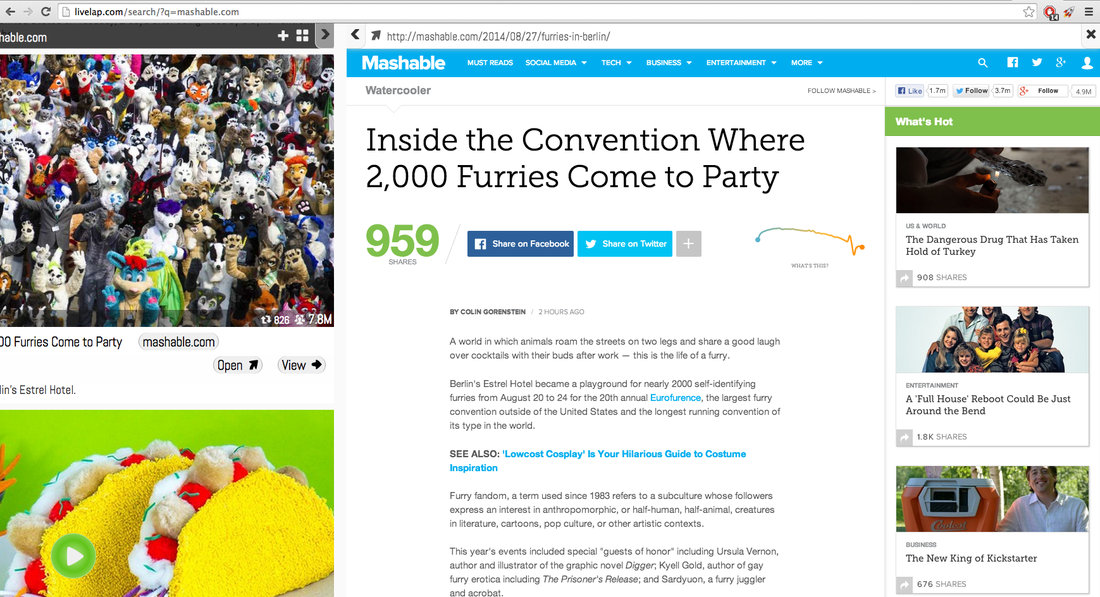
An example of how your content will look in Livelap is shown below. Example for: http://mashable.com/2014/08/27/furries-in-berlin/

We aggregate content by domain and show a visual overview of the latest content from your site. An impression for mashable.com is shown below.
Users can view the meta data of your content and we offer a preview (if not disabled by the site owner) of the page. This shows the content in an embedded iframe alongside the content details. A clickable link is shown above the preview, so it is clear to the user that the content is from another site. An example of the user experience is shown below.
Valid content
Livelap is a visual discovery tool, so we can't accept every link. The following rules apply before content is added to Livelap:
- A media image is required (og:image, twitter:image, or other standard image meta tags)
- Minimum resolution of 160x160 pixels for the image
- No adult, explicit, gambling, deceptive, spam, scam, explicit duplicates or otherwise harmful content is allowed.
Prevent Livelap from indexing your content
If you don't want your pages to be indexed by Livelap that's ok. You can limit or block LivelapBot in the following ways.
Use the "livelap:index" HTML meta tag to prevent Livelap from indexing
If you add the following HTML meta tag to the HEAD section of your pages, that page will be ignored by Livelap.<meta name="livelap:index" content="noindex"/>
Use the "robots" HTML meta tag to prevent all robots from indexing
If you add the following HTML meta tag to the HEAD section of your pages, that page will be ignored by web bots, incl. Livelap.<meta name="robots" content="noindex"/>
Use the "X-Robots-Tag" "noindex" HTTP header to prevent all robots from indexing
If you add the following HTTP header to your web response, that page will be ignored by web bots, incl. LivelapHTTP/1.1 200OK X-Robots-Tag: noindex
More information on the use of the robots tags can be found here: https://developers.google.com/webmasters/control-crawl-index/docs/robots_meta_tag
Prevent Livelap from previewing your content
If you want your pages to be indexed by Livelap, but you don't want your site to be previewed from within Livelap, you can add the following code.
Use the "livelap:preview" HTML meta tag to prevent Livelap from previewing your site
If you add the following HTML meta tag to the HEAD section of your pages, that page can't be previewed from within Livelap.<meta name="livelap:preview" content="no">
Use the "X-Frame-Options" HTTP header to prevent page previews
If you add the following HTTP header to your web response, that page can't be previewed from within Livelap.HTTP/1.1 200OK X-Frame-Options: SAMEORIGINorX-Frame-Options: DENY
Livelap does not support the ALLOW-FROM value for X-Frame-Options. More information on X-Frame-Options can be found here: https://developer.mozilla.org/en-US/docs/Web/HTTP/X-Frame-Options
What about robots.txt
Livelap does not currently check your /robots.txt file to determine if a link can be indexed or not. We are currently developing this feature. Please use one of the above mentioned methods to limit indexing. You can also request a full domain opt-out by contacting us